Which city’s rail system has the best Walk Score?
Last week, David Klion computed the Walk Score for all Washington Metro stops. How does Metro stack up to the other heavy rail systems in the United States? The answers may surprise you.
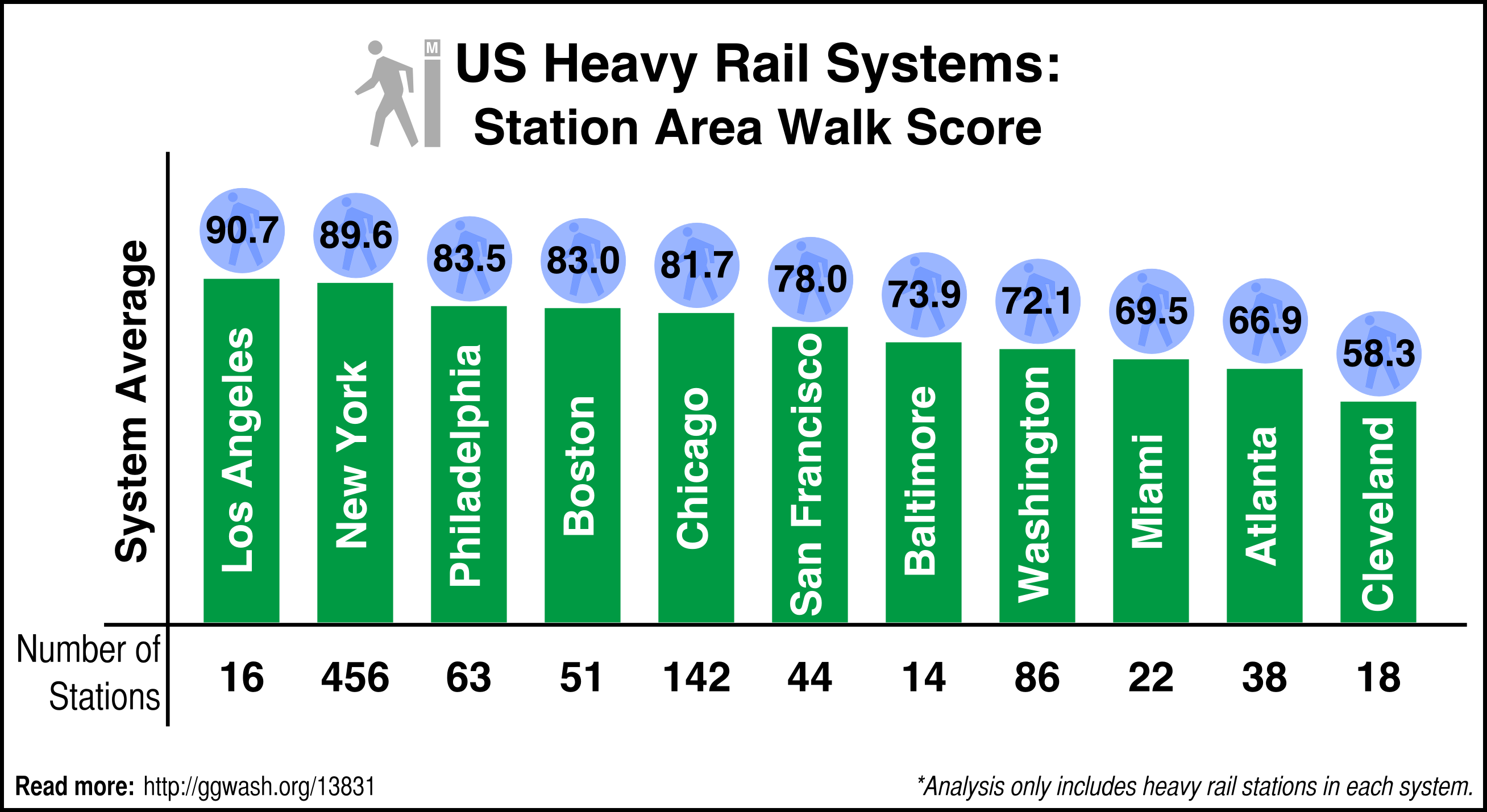
I analyzed the 11 heavy rail systems in the United States. Some of these cities also have light rail, commuter rail, or other transit systems, but I didn’t count those. That means in Boston, I looked at stations on the Red, Blue, and Orange lines, but not Green. (Why?)
I also combined heavy rail stations from multiple operators in the same region. For example, the Philadelphia score counts both SEPTA and PATCO heavy rail stations. New York’s includes PATH and the Staten Island Railway (SIRT).
And the winner is… Los Angeles?
I was surprised by the results. Los Angeles scored the highest! I certainly did not expect that. Though in hindsight, it makes a good deal of sense.
Los Angeles has only 2 heavy rail lines, the Red and Purple lines. Those lines are confined to a relatively small area in the LA Basin, with the exception of 2 stations on the Red Line in the San Fernando Valley. And while Southern California has a reputation for being sprawling, the LA Basin is actually fairly dense, especially where the Metro has been built. As a result, its score isn’t dragged down by suburban park and ride stations.
In the same respect, I was surprised that BART scored better than WMATA. Large portions of the DC system serve areas that are urban or urbanizing. In contrast, BART’s system is much more suburban-oriented and has very little in the way of urban circulation.
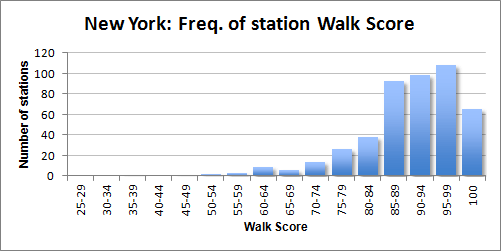
Also surprising is that New York is not an outlier. It does come in a close second to Los Angeles, but I really expected it to be off the charts compared to everyone else. The New York City Subway alone scores 90.47 without PATH and SIRT, still just below LA; SIRT averages 71.45 while PATH is higher, 92.23, but its relatively small size (13 stations) means it doesn’t change the New York average even a tenth of a point.
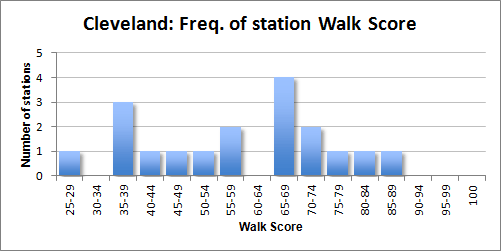
What is not very surprising is that the sunbelt cities (except LA) score more poorly than the more urban older cities (except for Cleveland). Cleveland is at a disadvantage because of the structure of its transit system. The system only has one stop in the central business district, and that station’s score isn’t that impressive anyway, which harms the average.
Distribution matters
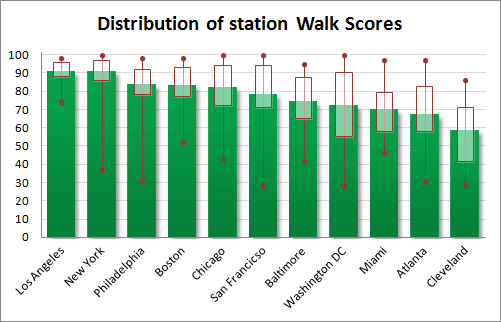
The chart above shows how Walk Scores for stations in each system are distributed. The green bars give the average score. The rectangle shows the 25th and 75th percentiles, and the lines with dots at each end show the highest and lowest Walk Scores for any station in that system.
At the high end, several cities had at least one station (sometimes several) with perfect 100-point scores. The lowest score for any station nationwide was 28 points. Two stations in the Washington region — Arlington Cemetery and Morgan Boulevard — and one station in San Francisco — North Concord/Martinez — had that score.
The distribution is important in understanding how well distributed the well-scoring stations are in the system.
In Washington, the distribution is weighted more toward good-scoring stations, but there are still a lot of poor-scoring stations, too.
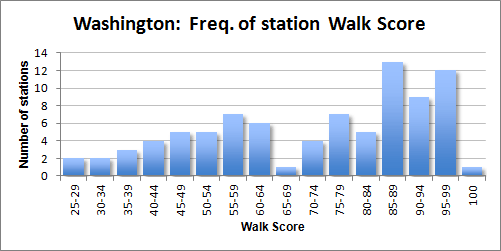
Compare that to San Francisco’s BART, where there are fewer poor-scoring stations. Instead, there are a large quantity of stations in the middle of the distribution.
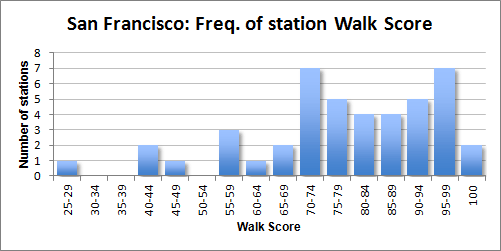
New York and Cleveland offer contrast to each other. While most New York stations score very well, Cleveland’s don’t rank above medium.
Limitations
The Walk Score algorithm is not perfect. It works by calculating the quantities and distances of various amenties. There are other factors which it does not measure that help to define the walkability of an area.
For example, a street grid makes an area much more walkable than a sprawling network of superblocks and culs-de-sac. The quality and proliferation of sidewalks also influences walkability. But these factors aren’t currently part of Walk Score; there’s no good data file for Walk Score to use that shows where there are and aren’t good sidewalks, for example.
Regardless, Walk Score gives us a standard and fairly good measure to compare transit stations (and systems) to each other.
Why I didn’t count light rail or other transit
I’m sure this will prove to be controversial, and that’s fine. I did not include the light rail elements of systems in cities like Boston for 3 primary reasons:
- Peer comparison: I wanted to create an apples-to-apples comparison, as best as possible. While the Washington Metro is easily comparable to BART, it doesn’t make as much sense to compare a Metro stop to a Muni LRT stop on the west side of San Francsico that is just a sign on a telephone pole.
- To limit the scope: This project took a good amount of time as it was. I did not want to extend that time by trying to measure too much. Besides, I (or someone) can always do a follow-up with light rail.
- To avoid “mode creep”: If we take Boston as an example, limiting the scope of the survey to heavy rail avoids the mode creep that can exacerbate the problems listed above. If I were to consider the Green Line, I would need to consider all of it. And if I’m considering the street-running portions of the Green Line, how can I not consider the full subway portions of the Silver Line in East Boston? And then would I not have to also include the Washington Avenue portion, that is essentially arterial bus?
This analysis is limited, as any analysis would be. I chose to try to keep it from expanding too far by limiting it to one mode. It would be interesting to look at the omitted lines, and perhaps that will happen in a future analysis.